
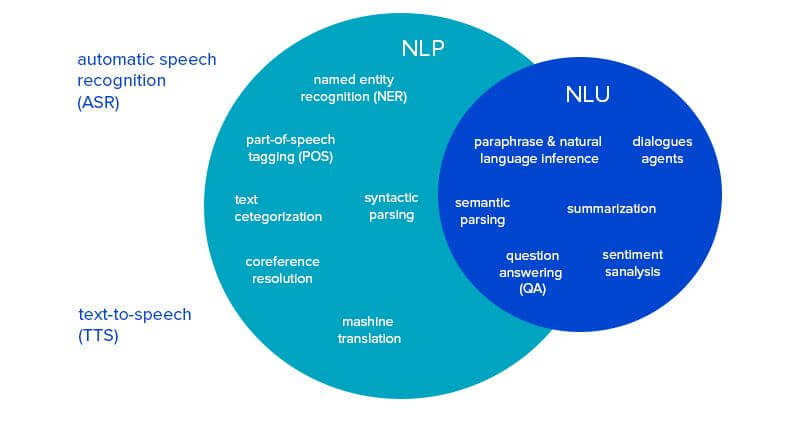
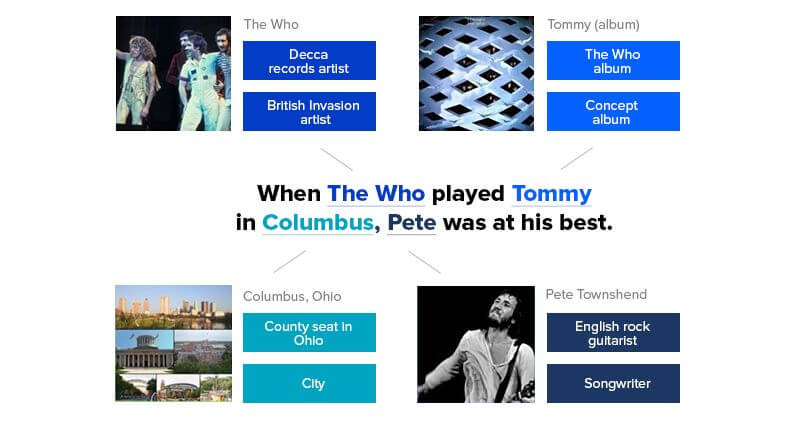
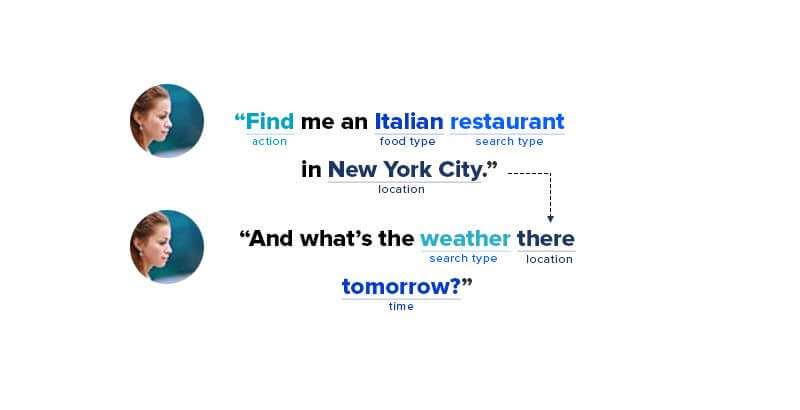
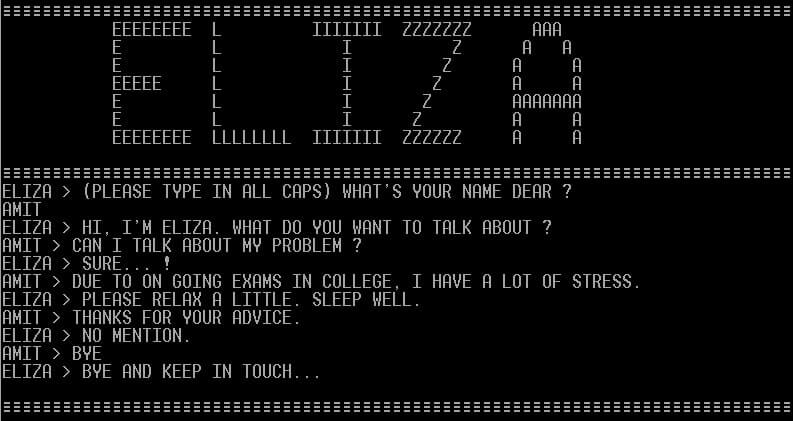









Skip the section
Related Insights

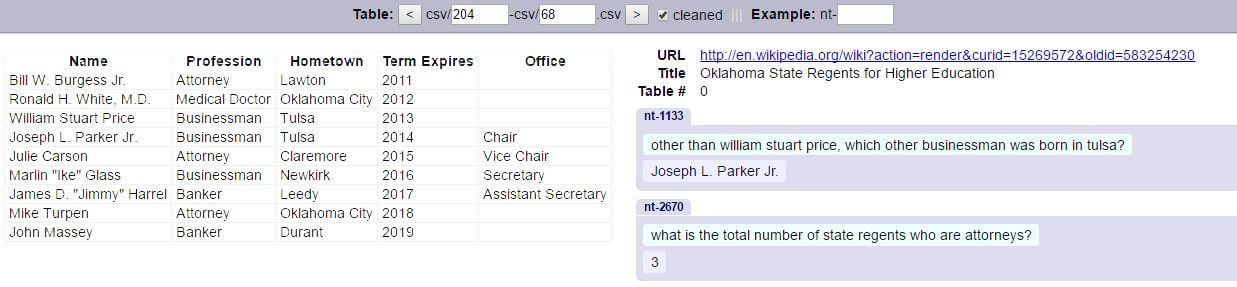
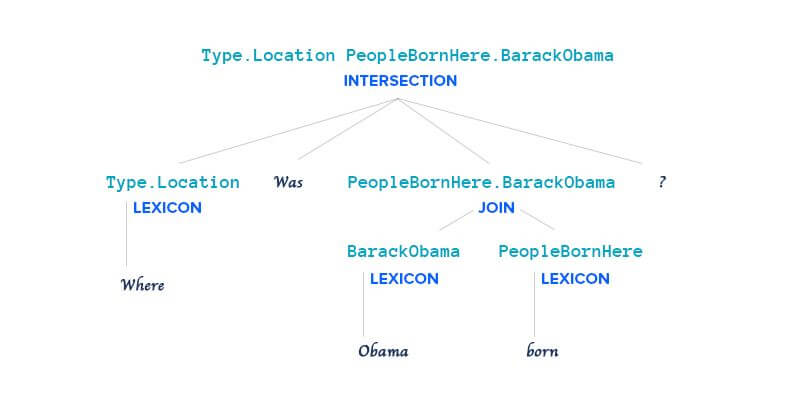
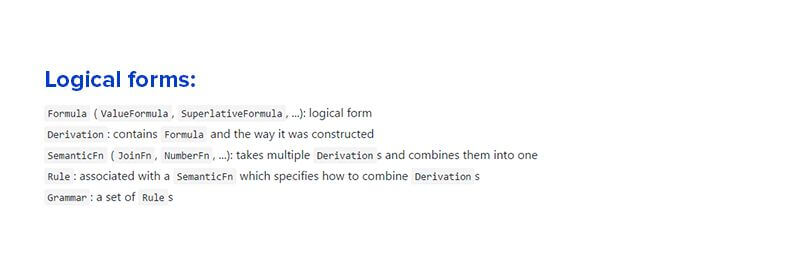
Article
How LLMs Think: Understanding the Power of Attention Mechanisms
View article

R&D
Enhancing Software Development with AI Tools: A Practical Look at Cursor IDE
View article
Article
Understanding Agentic AI: Benefits, Applications, and Future Trends
View article

Article
Essential Guide to LLMOps: Key Insights and Implementation Strategies
View article

Article
Strategic Technology in 2025: An Expert Assessment of Market Predictions
View article

Case studies
Enhancing Customer Support Efficiency with AI-Powered Knowledge Management
View article

Article
Supervised vs Unsupervised Learning: Differences, Applications, and Market Trends
View article

Article
The Best LLMs for Enhanced Language Processing in 2025
View article


