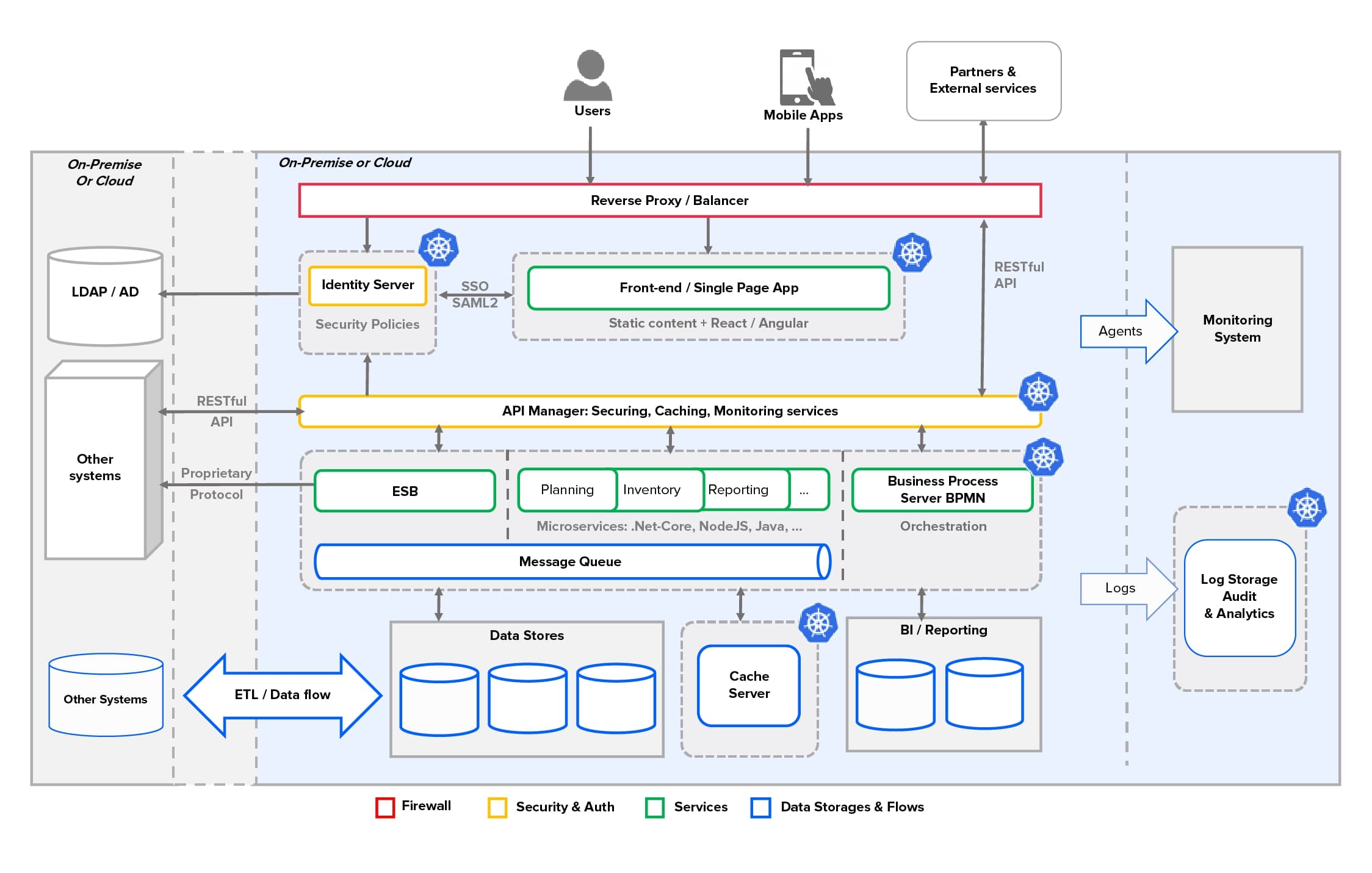
Main components and their functions in the architecture explained
| Reverse Proxy/Balancer | Acts as a primary firewall that restricts access from the Internet and intranet to sub-network where middleware is located. Could provide a balancer functionality, including legacy components that are not hosted under container orchestrator (kubernetes*). |
| Identity Server | Implements the SSO login process. Manages access policies. Handles several user stores. Provides role-based access functionality. |
| API Manager | Authenticates and authorises API requests from any client or device. A single point of audit logging. API and Application Lifecycle Management. API documentation and mocking. Standardise communication protocols, for example, to HTTPS/JSON. |
| Services/Microservices | Could be hosted in isolated containers and managed by container-manager (like kubernetes). This system could be easily scaled horizontally, and for microservices, even by a single service. It's possible that the components like BPS, ESB, Front-End are also considered as a service. |
| Message Queue | Transport for asynchronous and guaranteed message delivery. Helps to protect your enterprise systems and partner’s services from being overloaded. |
| ESB | In the modern world, microservices could be considered a deprecated technology, but it still provides a large set of connectors for different systems that allow exposing new services with configuration only. On the other hand, the new open-source cloud-native Ballerina language enables you to create integration services with minimal code. And each day it's extended with new connectors and features. |
| Business Process Server | Executes long-running stateful processes that enable user interaction. When all required business functions are covered with services, the cross-systems business process automation becomes an easy task. |
| ETL/Data Flow | Some business functions require a large amount of data transformation, synchronisation, delivery and historicization. In this case, it's possible to use modern visual tools that allow for the building of data flows using only configuration, and to expose it as a service or run it by a schedule. |
| Container Orchestration | System for automating deployment, scaling and management of containerised applications. The components that are usually managed by container orchestrator are marked with |
How to implement components
Some components could be omitted or reused from the current enterprise architecture; however, we try to compose the best (from our point of view) open-source component implementation scheme to minimise initial project investments and ownership costs.
As soon as we aim to integrate with the cloud, we use docker for containerisation and kubernetes as an orchestrator for containers, since these tools are market leaders.
| Group | Component | Tool/Solution | Details |
| (Micro)Services Architecture | Frameworks | Moleculer/NodeJS | Progressive microservices framework for Node.js. |
| Ballerina.io | Cloud-native programming language to write microservices that integrate APIs. | ||
| .NET Core | .NET Core is an open-source, general-purpose development platform that is cross-platform (supporting Windows, macOS and Linux). | ||
| Spring Framework | The most well-known Java framework that includes different enterprise application integration sub-projects such as Spring Cloud and Spring Data Flow. | ||
| Ratpack.io | Ratpack is a set of Java libraries for building scalable HTTP applications, tiny codebase, useful for groovy developers. | ||
| API Managers | WSO API Manager | An open-source approach that addresses full API lifecycle management, monetisation and policy enforcement. A central component used to deploy and manage API-driven ecosystems. | |
| Kong | Next-generation API platform for multi-cloud and hybrid organisations. | ||
| Legacy as Web / REST Service Service-to-Service Integration |
WSO2 Enterprise Integrator |
WSO2 Enterprise Integrator is an open-source product for cloud-native and container-native projects, enabling enterprise application integration experts to build, scale and secure, sophisticated integration solutions to achieve digital agility. Unlike other integration products, WSO2 Enterprise Integrator already contains integration runtimes, message brokering, business process modelling, analytics and visual tooling capabilities. |
|
| SSO, Access Policies | WSO2 Identity Server | WSO2 Identity Server is an open-source IAM product optimised for identity federation and SSO with comprehensive support for adaptive and strong authentication.
It helps identify administrators to federate identities, provide secure access to Web/mobile applications and endpoints, and bridge versatile identity protocols across on-premises and cloud environments. |
|
| RedHat Keycloak | Keycloak is an open-source Identity and Access Management (IAM) solution aimed at modern applications and services. It makes it easy to secure applications and services with little to no code. | ||
| Data Integration | ETL / Data-Flow | Apache NiFi | Apache NiFi supports powerful and scalable directed graphs of data routing, transformation and system mediation logic. |
| Pentaho | Quickly and easily delivers the data to your business and IT users — no coding or complexity required. | ||
| Message Queue | Rabbit MQ | RabbitMQ is lightweight and easy to deploy on-premises and in the cloud. It supports multiple messaging protocols and can be deployed in distributed and federated configurations to meet high-scale, high-availability requirements. | |
| Apache Active MQ | Apache ActiveMQ is the most popular and powerful open-source messaging server. | ||
| Business Process Automation | BPMN | Camunda BPM | An open-source platform for workflow and decision automation that brings business users and software developers together. |
| WSO2 BPS/Enterprise Integrator | Scalable and lean Business Process Server (BPS) helps to increase productivity and enhance competitiveness by enabling developers to easily deploy business processes and models written using BPEL and BPMN. | ||
| Alfresco BPM / Activiti BPM | Alfresco Process Services (powered by Activiti) is an enterprise Business Process Management (BPM) solution targeted at business people and developers. Includes native iOS and Android apps that help you operate your business processes. Not fully open-source, but almost all open-source BPM systems built on top of Activiti BPM. |
Cloud provisioning and deployment
While cloud services become more and more affordable, customers often consider changing their cloud provider because of a better price or higher performance. Often, they opt for a multi-cloud infrastructure to be able to choose the best service from different providers. This means our enterprise application integration approach needs to be cloud-agnostic and provide a universal solution that could fit any cloud.
Infrastructure as code is the best approach to achieve this goal, and our choice is Terraform as it allows you to safely and predictably create, change and improve infrastructure based on the declarative configuration files that can be shared among team members, treated as code, edited, reviewed and versioned. So, it’s a versioned infrastructure!
What’s also great about our method is that we use self-configured docker containers for testing and development project phases. Those containers have all layers except the last layer with the development artefacts. The last layer is self-deployed during the container start-up, which saves time for recompiling containers and allows us to store containers publicly on dockerhub since it does not contain any private information/artefacts.
Follow the below link to our GitHub repository where you can find a demo terraform project that creates a kubernetes cluster at AWS cloud with some components running on it. It will take you about ten minutes to create your cluster in the cloud! https://github.com/eleks/integration-platform
Enterprise application integration FAQs
1. What’s different about this approach and what are the benefits for my organisation?
Related Insights